Безопасность в Дельфи
Кому не терпится увидеть код он вас ждет в конце статьи А сюда вернетесь потом )
Мы хотим прописать контрольную сумму в файл, но не хотим чтобы контрольная сумма файла изменилась. Задача довольно интересная. Есть другие способы, например проверять контрольную сумму, но не учитывать те 4 байта, где хранится контрольная сумма. Но скорректировать такой файл не представит большого труда. Это не сильно усложнит жизнь кракеру. И таким способом нельзя прописать одно значение CRC в разные места программы, что сводит на нет использование более чем одной процедуры контроля CRC. Хотя можно, но через все эти места придется прыгать во всех процедурах, а кракер вычислит и пропатчит их гораздо быстрее, чем вы их туда пропишите. Поэтому забываем про эти способы :). Поскольку алгоритм вычисления CRC основан на последовательной, побайтовой работе над буфером операциями XOR, сдвига и хранения результата вычисления в 32 разрядном аккумуляторе, логично предположить, что 4-мя последовательными байтами можно подогнать контрольную сумму к любому числу. С другой стороны алгоритм вычисления CRC является биекцией и может быть обращен. Причем не прилагая особых усилий, не выполняя никакого подбора. Просто считается в обратном направлении.
Для простоты пояснения и понимания, ячейка исходного защищаемого выполняемого модуля, в которой хранится контрольная сумма (назовем ее B1), должна быть статической непрерывной переменной, объявленной в области кода или данных программы. Но вам ничто не мешает хранить значение CRC в раздробленом на части виде, зашифрованное по какому либо принципу. В реальной защите это даже приветствуется. :)
Значит значение CRC хранится в четырех последовательных байтах. Снова таки для простоты примера, за этими четырьмя байтами идут еще четыре байта (назовем их B2) которые будут использованы для коррекции CRC файла, после того как мы в файл пропишем число, определяющее его CRC.
В реальности блоки байт B1 и B2 лучше разнести в разные места исходного кода. И сами корректировочне байты B2 можно использовать где-то в бессмысленных вычислениях, чтобы линкер построил на них ссылку: дескать это какие-то нужные данные. Важно только, чтобы корректировочне байты были в четырех последовательных байтах файла и находились, внимание, за последним измененным блоком, в зависимости от того, откуда вы считате CRC (с начала файла или с конца). А поскольку CRC считается для внутреннего использования вам никто не мешает считать его с конца файла к началу, но я не рекомендую, PE заголовок легко патчится. Изменять вы можете хоть весь файл но последние 4 последовательных байта смогут привести CRC к нужному результату. В принципе задачу можно решать с другой стороны, например задаться целью, что CRC конечного файла должен быть например 0123ABCD. Это число можно будет перед компиляцией прописать в условие процедуры проверки CRC. В этом случае уже не придется его прописывать в файл. Для этого достаточно будет подогнать четыре корректировочных байта B2 так, чтобы контрольная сумма файла стала именно 0123ABCD. Но здесь важно помнить, что вряд ли у вас получится разместить корректировочные байты в конце файла только при помощи компилятора. Дельфи еще в конце файла приложит таблицу релокаций и информацию о версии, если она включена в проекте. К тому же, из соображений простоты взлома, размещать коректировочные байты в конце файла, плохая идея. Поэтому придется реверсно выполнять алгоритм CRC (считать CRC файла от его результата к его началу проходя алгоритм CRC в обратном направлении, то есть получить CRC в заданной точке, имея файл и его CRC, но при условии прохождения алгоритма в обратном направлении) с конца файла через неизменяемые байты до последнего корректировочного байта. Говоря "последнего", я имею ввиду последнего в абсолютном его индексе, то есть при реверсировании CRC не нужно их учитывать. В общем реверсное выполнение алгоритма я бы разделил на три типа:
- первый вычисление начального CRC имея конечный CRC и буфер,
- второй это поиск последовательности байт которые приведут к нужному CRC если его начать с определенного CRC. Дальше нам потребуется именно второй вариант алгоритма вычисления CRC.
- третий, он собственно разновидность второго, это восстановление последовательности байт буфера CRC которого считали имея конечный CRC и длину буфера. Правда тут уже появляются неоднозначности, иначе CRC-32 был бы супер архиватором со 100% восстановлением информации. На длинных буферах вариантов будет очень много. Ведь последние 4 байта дадут нам нужный результат. Вот восстановление одиночной ошибки если мы знаем где она произошла это другое дело. Но и тема для другого разговора.
Перед компиляцией первой (защищенной) программы кладем в эти 8-байт (B1 и B2) уникальную сигнатуру.
У меня нормально прошла такая сигнатура.
Определяемая здесь сигнатура обязательно должна быть уникальна по всему файлу полученному в результате компиляции потому, как второе приложение которое будет прописывать контрольную сумму и корректировочные байты должно искать эту сигнатуру по всему исходному файлу, и найти обязательно то что нужно, а не кусок кода или каких либо важны данных. Хотя если вы вручную вычислите точное смещение наших 8 байт то никто вас не заставляет делать сигнатуру уникальной.
В прилагаемом коде примера эта сигнатура размещена прямо в коде процедуры, во мне живет старая любовь к программам у которых сегмент кода и данных были одним целым. И обратите внимание что процедура поиска сигнатуры не имеет контроля уникальности сигнатуры. Это значит что она найдет только первую сигнатуру и закончит поиск. Для приведенного примера этого достаточно.
Для повышения быстродействия можно вычислять CRC блоками запоминая промежуточные значения. Но мне было лениво, тем более что особых тормозов я не видел :) В примере у меня на это уходит меньше секунды... Расчет CRC начнем со стартового значения C0. смотрите рисунок 1.
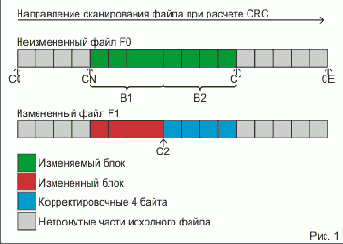
Вот пошаговый алгоритм подготовки входных данных для второго варианта алгоритма реверсирования о котором будет говориться ниже.
- 1) Вычисляем контрольную сумму, начиная со значения C0, от начала файла F0 до конца корректировочного блока B2. Запоминаем ее в C1
2) Начиная со значения C1 продолжаем расчет CRC до конца файла F0. Сохраняем его в CE. Это будет CRC исходного файла, которую мы и пропишем в нашу ячейку B1.
3) Прописываем CE в B1. За этим блоком идет 4-ре поправочных байта. Их мы скоро будем вычислять.
4) Рассчитываем CRC измененного файла для измененного блока B1 (красного цвета), до начала блока с корректировочными байтами B2 не включая поправочне байты! В файл должны быть внесены все изменения, чтобы осталось записать только корректировочные байты.
Что нас интересует в итоге?
C1 - CRC к которой должен быть приведен фрагмент файла F1 от начала файла до конца блока B2
C2 - CRC в точке перед началом блока B2 которая получилась после внесения изменений в блок B1, мы записали туда CRC файла. Подчеркнуто специально, потому что пример несколько неудачен: конец блока B1 сливается с началом блока B2. Дальше на рисунке 2 это видно более наглядно.
Теперь пришло время взяться за алгоритм подбора корректировочных байт. Понимая о ненужности изобретать велосипед я полез в интернет. Тот предлагает массу источников об математических основах CRC и также о способах его реверсирования, вычисления последовательности байт которые дают нужный CRC из некоего стартового значения CRC. Нам нужен второй вариант алгоритма реверсирования о котором уже упоминалось выше - поиск последовательности байт приводящих CRC к нужному значению.
Статья Андрея Рубина, которую я нашел в Королевстве Дельфи, была совершенно мне непонятна. Я никак не мог понять, как применить приведенный код реверсирования, пока не начал вручную реверсировать CRC по его реальному алгоритму. В общем можно сказать что для той статьи не хватает моих рисунков и точной формулировки параметров его процедуры. И после этого я решил написать статью-разъяснение специально для Королевства Дельфи и включить ее в проект АКМ. В проекте я использовал процедуры приведенные Андреем Рубиным. Из его довольно объемного проекта я вытащил только процедуры касающиеся расчета CRC и его реверсирования. Что касается интересующей нас, процедуры вычисления последовательности байт по исходному и конечному CRC, вношу ясность.
Итак в конце статьи конкретный работающий пример из двух приложений. Компилируйте, тестируйте. Для того чтобы использовать приведенный код в реальном приложении защищенном от изменения нужно предпринять некоторые действия.
Я считаю что описание способов замыливания мозгов кракера дело неблагодарное, их масса, но в силу каких-то высших причин все они обходятся. Данный пример можно использовать всего лишь как одну из подножек подставленных кракеру. Чем больше вы соберете таких подножек тем дольше проживет ваше приложение до момента взлома. Надо заметить, что самое слабое место в предложеном способе контроля целостности приложения - это чтение файла с диска. Даже чтение файла на уровне физических секторов (что уже является слишком навороченным для систем защиты) не мешает хакеру подсунуть настоящий неизмененный файл, или же перехватить операцию чтения файла с диска. Поэтому не путайте себя и слишком усердствуйте в количествах способов контроля CRC. Два, максимум три варианта процедур которые различаются своим кодом. Я имею ввиду чтобы код этих нескольких процедур не вычислялся по одинаковым сигнатурам. Один вариант можете взять из примера, другой вариант из статьи Сергеем Паруновым. Ассемблерный код гораздо приятнее паскалевского разбавлять мусором для создания двух, трех экземпляров непохожих друг на друга процедур.
Первый "громкий" вариант срабатывания защиты целостности файла нужен для легальных пользователей (для предупреждения о вирусе или PE архиваторе) и на съедение кракеру. Остальные варианты должны просыпаться скажем раз в недельку и молча проверив CRC выставить "черные" метки, и дальше по вашей тихой схеме срабатывания защиты. Еще одно слабое место versioninfo. Идеальное место для разгула коррекции CRC. В конце статьи приведены ссылки на некоторые из найденых мной источников. Среди них есть статья о 64 битном CRC. В два раза большая таблица образующего полинома, в два раза большее время работы, но зато в два раза более длинный хеш и самое важное, отступление от стандарта. Я не припомню чтобы где-то видел 64 битный CRC. MD5 да видел, но это немного другое. Алгоритм реверсирования CRC-64 примерно такой же. Правда корректировочных байтов будет в два раза больше. Кстати о таблице образующего полинома... Чтобы ее случайно не нашли возьмите другой образующий полином или создавайте таблицу динамически во время исполнения кода.
Данная методика позволяет добавить в файл еще какую либо информацию о характеристиках запускаемого файла например о его размере, даты создания-изменения. Данным способом в исполняемый файл можно прописывать некоторую информацию о персонализации генерации программы. Например вы можете во все копии программы элементарно без перекомпиляции программы прописать уникальные серийные номера и привязать их к легальным пользователям. Кроме того если вы внимательно посмотрите на заголовок EXE файла, построеный дельфи, то увидите что контрольная сумма в двойном слове там равна 0. Тоже вариант туда что-то прописать :) например оригинальную контрольную сумму. Для этого можно использовать функцию MapFileAndCheckSumA которая живет в imagehlp.dll. Я ее также привел в коде примера. К сожалению алгоритм вычисления CRC функцией MapFileAndCheckSumA несколько отличается от алгоритма приведенного в статье, поэтому совместное использование этого метода и приведенного метода с коррекцией становится практически невозможным.
Я еще раз говорю что приведенный способ защиты кода программы от изменения не панацея. Это просто один из шагов усложняющих взлом.
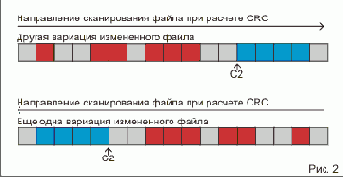
на рисунке 2 показаны другие способы внесения изменений в файл, что можно изменять в файле и как в каком направлении проводить расчет CRC. Но в случае обратного сканирования файла использование CRC в заголовке файла становится затруднительным так как разместить после него коректировочный блок становится сложным.... Хотя нет! В EXE заголовке есть свободные (reserved) байты. Но здесь снова встает извечное противоречие... Легко вам - легко кракеру....
В архиве исходные тексты, проверенные под Delphi7.
Скачать тексты Self_CRC_Check.zip (14.1 K)
Смотрите по теме:
- Почти всё, что вы хотели узнать, но боялись спросить о Crc32
- Почти всё, что вы хотели узнать, но боялись спросить о Crc32. Продолжение.
- Контрольные суммы и CRC.
- Статья Anarchriz/DREAD Copyright (c) 1998,1999 by Anarchriz с математическими выкладками о реверсировании CRC ( перевод Sergey R. )
Виталий Царегородцев,
aka younghacker
Специально для Королевства Delphi
